
How Stable Diffusion, DALL-E 2 and MidJourney work?
In this article, we will take a simplified but slightly technical look at how these AI models manage to create images like the ones from the article.
Introduction
This year we have seen some amazing developments in the domain of image generation and while I predicted we would see some developments on the domain of generated content this year I am still in awe to how far we've come.


There are many different players in this new space of image generation, some of the most popular include DALL-E 2, MidJourney and Stable Diffusion.
This article focuses on the high-level fundamentals to these models but there are differences between them which I might tackle in a separate post.
With that disclaimer given, let's start (source)!
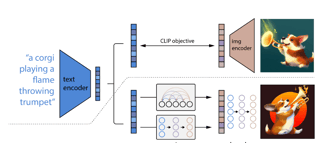
The high-level view of the components
AI image generation models typically consist of several key components that work together to create images from text prompts. Let's break down each component and its role in the process.
Text Encoder: The process begins with a text prompt, such as "a corgi playing a flame-throwing trumpet." This prompt is fed into a text encoder model, often referred to as CLIP (Contrastive Language-Image Pre-training). CLIP transforms the textual information into a vector of numbers called text embeddings. These embeddings capture the semantic meaning of the text, with closely related concepts represented by numerically similar vectors.
Image Encoder: In addition to text embeddings, these models also utilize image embeddings. Similar to text embeddings, image embeddings are numerical representations of images. The image encoder takes an image as input and generates a corresponding vector of numbers. Closely related images have numerically similar embeddings, allowing the model to understand visual concepts.
Diffusion Decoder: The diffusion decoder, also known as the image decoder, is responsible for generating the final image from the image embeddings. It uses a stochastic process to iteratively refine a noisy initial image based on the information contained in the embeddings. The decoder starts with random noise and gradually adds more detail and structure to the image over multiple steps, guided by the embeddings.
When a user provides a text prompt, the text encoder (CLIP) converts it into text embeddings. These embeddings are then used to guide the diffusion decoder in generating an image that matches the semantic content of the prompt. The image encoder ensures that the generated image embeddings are similar to the text embeddings, allowing for a strong correlation between the textual description and the resulting image.
It starts off with a text prompt (e.g. a corgi playing a flame throwing trumpet) and it is used as input into a text encoder model. In simple terms, this model transforms the textual information into a vector of numbers, this is called text embeddings. A simplified example of this is that the word "cat" can be represented by [0.3, 0.02, 0.7], the word "dog" by [0.6, 0.02, 0.7] and the word "bridge" by [0.01, 0.5, 0.01].
A key characteristic of these embeddings is that closely related semantic concepts are numerically close to one another. This is an extremely powerful technique used for a variety of different problems.
Another key component is the ability to generate image embeddings. They are similar to text embeddings in the sense that it's a numerical representation of an image. A simplified example of this is that a photo of a "lion" can be represented by [0.1, 0.02, 0.6].
Similar to text embeddings, a key characteristic is that closely conceptually related images are also numerically close to one another. In addition to this, these text embeddings and image embeddings are also similar to one another for the same concept, meaning that a photo of a "lion" and the word "lion" generate closely related embeddings.
The other key is an image decoder, also called a diffusion decoder, that takes the image embeddings and stochastically generates an image using the embedding information, which will be discussed in more detail below.



On this example, given an input image and trying to encode with CLIP (generating image embeddings) and then decoding with a diffusion model - using the image embeddings to generate the final image - we can see that there's some information loss that happens throughout the process but the variations preserve most key information, such as the presence of a clock in the painting and the overlapping strokes in the logo or the overall surrealism in the painting.
How do you connect "A cat riding a skateboard" to an image and vice-versa and why it matters?
The short answer is, as we seen above, through the use of text embeddings and image embeddings.
One of the key challenges in generating images from textual descriptions is establishing a meaningful connection between the text and the visual representation. This is where the CLIP (Contrastive Language-Image Pre-training) model comes into play. By representing text and images in a shared embedding space, CLIP allows the model to understand the relationship between the two modalities.
During the training process, CLIP is exposed to hundreds of millions of images along with their associated captions. This extensive training data teaches the model how to map text snippets to their corresponding visual representations. The goal is to create a model that can generate similar embeddings for a photo of a plane and the text "a photo of a plane," indicating that the model has learned to associate the concept of a plane with both its textual and visual representations.
The importance of CLIP in the image generation process cannot be overstated. Without the ability to connect text and images through embeddings, it would be impossible to determine if a generated image is relevant to the input text prompt. Imagine a scenario where a monkey randomly draws pixels on Photoshop for an infinite amount of time. Using CLIP, we could automatically discard any irrelevant paintings and keep only the ones that are conceptually similar to what we want, saving us from wasting time and resources on unrelated outputs.
However, waiting for an infinite amount of time is not practical, and that's where the ingenuity of researchers comes into play. By leveraging the power of CLIP and combining it with advanced image generation techniques, such as diffusion models or generative adversarial networks (GANs), researchers have developed models that can create highly relevant and detailed images from textual descriptions in a much more efficient manner.
Generating the actual image
Once the text prompt has been converted into embeddings using the CLIP model, the next step is to generate the actual image. This is where diffusion models, also known as diffusion probabilistic models, come into play.
Diffusion models work by starting with a noisy image and gradually denoising it over multiple steps until it converges to an image that closely resembles the original prompt. At each step of the generation process, the model uses the embeddings to guide the denoising process, adjusting pixel values based on what it considers to be the most probable representation of the image.
The training process for diffusion models is quite fascinating. These models are trained on a large dataset of "good" or high-quality images. During training, the model learns to corrupt the images by adding noise, gradually transforming them from clear pictures into fully noisy images. By doing so, the model gains an understanding of how to reverse the process and generate clear images from noise.
For example, if a diffusion model is trained on a dataset of human faces, it will learn how to gradually add noise to clear face images until they become completely noisy. Through this process, the model also learns how to remove noise from noisy images, step by step, to generate clear and realistic human faces. Once trained, the model can generate entirely new, never-before-seen human faces from random noise, guided by the embeddings derived from the text prompt.
It's important to note that diffusion models generate one of many possible images that express the conceptual information within the prompt. This is why you often see discussions and sharing of "seed" values in the AI image generation community. A seed value is a number used to initialize the random noise generator. By using the same seed value, along with the same prompt, parameters, and model, you can generate the exact same image every time. This deterministic behavior allows for reproducibility and enables users to explore variations of an image by changing the seed value.
In summary, diffusion models play a crucial role in generating the actual image from the embeddings derived from the text prompt. By gradually denoising a noisy image guided by the embeddings, diffusion models can create stunning, highly detailed, and semantically relevant images that accurately reflect the desired concepts and details expressed in the prompt.
The Technicals
At the heart of the diffusion model's denoising process is a neural network architecture called U-Net.
The U-Net architecture consists of two main parts: an encoder and a decoder. The encoder downsamples the input image through a series of convolutional and pooling layers, capturing the image's features at different scales. The decoder then upsamples the encoded features through a series of transposed convolutional layers, gradually reconstructing the image while preserving the spatial information.
The training process involves two main steps: the forward diffusion process and the reverse diffusion process.
In the forward diffusion process, the model learns to gradually add noise to the clean images over a fixed number of timesteps. At each timestep, the model applies a small amount of Gaussian noise to the image, slowly corrupting it until it becomes pure noise. The model is trained to predict the noise that was added at each timestep, conditioned on the noisy image and the timestep itself.
During inference, the model starts with a pure noise image and performs the reverse diffusion process. At each timestep, the model predicts the noise that needs to be removed from the noisy image, conditioned on the noisy image, the timestep, and the text embeddings generated by the CLIP model. By repeatedly removing the predicted noise at each timestep, the model gradually denoises the image, eventually converging to a clean image that reflects the conceptual information provided in the text prompt.
Let's see an example (source):






If this was enjoyable and you would like to know more about the subject or if you want to discuss more please reach out to me here.
All the illustrations were generated using Stable Diffusion on a custom model prompted about images of Portugal.
Additional reading:

